In machine learning, achieving high accuracy and superior predictions often requires more than a single model. Ensemble learning, a technique that combines multiple models to improve performance, has become a cornerstone of modern data science. Stacking and blending stand out as advanced strategies for achieving state-of-the-art results among the various ensemble methods. These methods allow data scientists to harness the strengths of multiple models, thereby overcoming individual weaknesses. Enrolling in a data science course in Pune can provide a deep understanding of these techniques, empowering you to implement them effectively in real-world scenarios.
Understanding Ensemble Learning
Ensemble learning combines predictions from multiple models to achieve better results than any single model. Popular ensemble techniques include bagging, boosting, stacking, and blending. While bagging and boosting, such as Random Forest and Gradient Boosting, are widely used, stacking and blending offer more advanced ways to combine models. These methods excel in capturing diverse perspectives and improving generalisation.
By joining a data scientist course, you can explore the fundamentals of ensemble learning, understand its various techniques, and apply them to datasets for maximum predictive power.
What is Model Stacking?
Definition
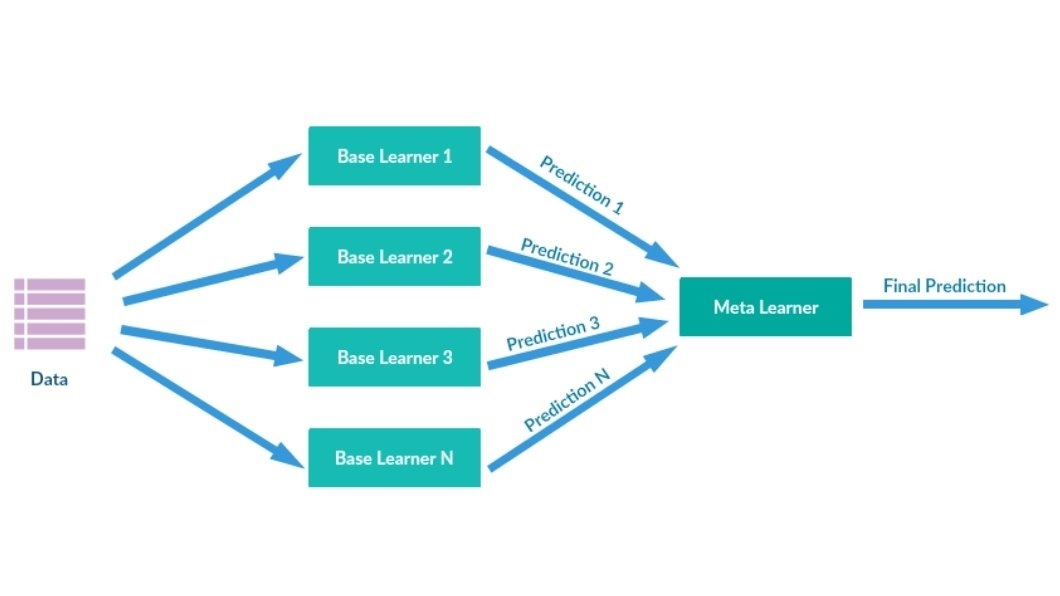
Model stacking is an ensemble learning technique that combines multiple base models through a meta-model (or second-level model). The base models generate predictions, which are then used as input features for the meta-model. This hierarchical approach allows the meta-model to learn how to combine the base models’ outputs best.
Process
- Training Base Models: Train several diverse models (e.g., decision trees, neural networks, and support vector machines) on the same dataset.
- Generating Predictions: Use these models to predict outcomes on a holdout dataset.
- Training the Meta-Model: Feed the predictions from the base models into a meta-model, which learns the optimal combination of these predictions to improve accuracy.
Mastering stacking can be a valuable skill, and enrolling in a data scientist course provides practical insights into implementing stacking in tools like Python or R.
What is Model Blending?
Definition
Blending is a simplified version of stacking in which the predictions of base models are combined using weighted averages or simple rules instead of a meta-model. It is less computationally intensive but still delivers significant improvements in predictive performance.
Process
- Divide the Data: Split the dataset into training and validation sets.
- Train Base Models: Train multiple models on the training set.
- Combine Predictions: Combine the predictions on the validation set using a weighted average or another aggregation method.
Although blending is simpler, its effectiveness lies in choosing appropriate weights or aggregation rules. A key focus of a data scientist course is gaining hands-on experience with blending techniques.
Key Differences Between Stacking and Blending
1. Complexity
- Stacking involves training a meta-model, making it computationally intensive.
- Blending uses simpler methods like weighted averages, making it easier to implement.
2. Data Requirements
- Stacking often requires an additional holdout set to train the meta-model.
- Blending can work directly on the validation set, reducing data requirements.
Understanding when to choose stacking versus blending is a crucial aspect of predictive modeling, which you can master in a data scientist course.
Advantages of Stacking and Blending
Stacking
- Diversity: Combines models with different architectures, capturing diverse perspectives.
- Improved Generalisation: Reduces the risk of overfitting by leveraging a meta-model.
- Flexibility: Works well with various types of models and datasets.
Blending
- Simplicity: Easier to implement and requires less computational power.
- Reduced Risk of Overfitting: Aggregation methods inherently limit overfitting.
- Scalability: Can be used effectively on large datasets with minimal preprocessing.
Both techniques are integral to building robust predictive models, and a data science course in Pune can provide a strong foundation in these methods.
Practical Applications of Stacking and Blending
1. Competition Success
These techniques are widely used in machine learning competitions like Kaggle, where even marginal improvements in accuracy can lead to winning solutions.
2. Financial Forecasting
Stacking and blending are invaluable in predicting stock prices, credit risks, and other financial metrics.
3. Healthcare
Ensemble methods improve the accuracy of disease diagnosis and treatment predictions by combining outputs from diverse models.
Enrolling in a data science course in Pune can help you apply stacking and blending to such high-impact use cases.
Challenges in Stacking and Blending
- Overfitting: Complex ensemble methods may overfit the training data, especially with insufficient data.
- Computational Cost: Stacking requires more computational resources due to the additional meta-model training.
- Hyperparameter Tuning: Balancing the weights in blending or optimising meta-model parameters can be time-consuming.
Learning to navigate these challenges effectively is critical to a data science course in Pune.
Tools and Frameworks for Implementation
Python Libraries
- scikit-learn: Offers tools for stacking and blending implementations.
- XGBoost: Widely used for blending due to its efficiency.
- Extend: Provides specialised functions for stacking.
Cloud Platforms
Cloud platforms like AWS, Azure, and Google Cloud allow you to efficiently implement and scale these techniques. Detailed guidance on using these tools is a core component of a data science course in Pune.
Conclusion
Advanced ensemble learning techniques like stacking and blending provide a powerful arsenal for achieving superior predictions. Combining diverse models and leveraging their strengths enables data scientists to tackle complex problems across industries. While stacking offers high accuracy with a meta-model, blending provides simplicity and scalability, making both techniques valuable for different scenarios.
To master these cutting-edge methods and gain practical expertise, consider enrolling in a data science course in Pune. Such a course will equip you with the theoretical knowledge and hands-on skills needed to excel in the competitive field of machine learning.
Business Name: ExcelR – Data Science, Data Analytics Course Training in Pune
Address: 101 A ,1st Floor, Siddh Icon, Baner Rd, opposite Lane To Royal Enfield Showroom, beside Asian Box Restaurant, Baner, Pune, Maharashtra 411045
Phone Number: 098809 13504
Email Id: enquiry@excelr.com