Introduction
Building efficient data pipelines is crucial in data science to ensure smooth data processing, analysis, and model deployment. The efficiency of applied data science depends on the accuracy of the predictions made using the principles of data science, the amount of data that backs analytics, the accuracy of the metrics that data science models evaluate in drawing conclusions, and how the models handle aberrations and outliners. These are some of the advanced skills that a data science professional needs to acquire for effectively using data for analyses. Continuous learning and updating skills, and attending a domain-specific Data Science Course and continuing to build on it on your own, make for an efficient data pipeline that keeps you relevant in your role and simplifies your work.
Building an Efficient Data Pipeline
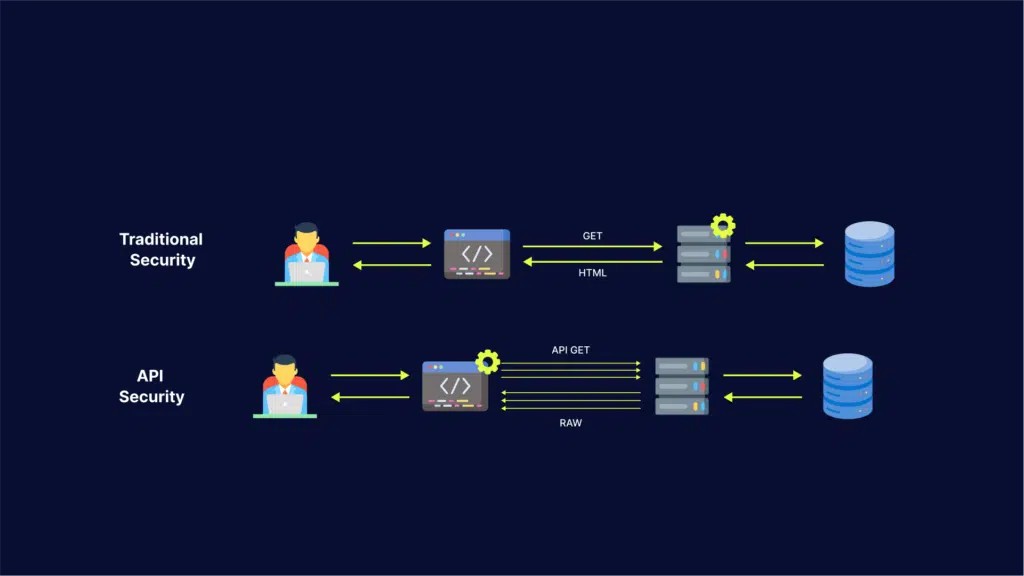
As data analysis is a step-by-step process, any laxity in any of the tasks involved will be carried forward and most likely, corrupt the subsequent steps. Right from collecting data to cleansing, and analysing data to reporting workable conclusions, there is no latitude for any leniency in the due-diligence and the commitment each task calls for. Grooming a data science professional involves instilling this mindset of thoroughness and insistence on accuracy in the learner. In tech-oriented cities where data science skills are sought by professionals, emphasis is placed on this this aspect of learning the technology. Thus, a Data Science Course in Hyderabad or Bangalore, or Delhi might begin by enlightening students on the importance of developing an effective data pipeline and adhering to it.
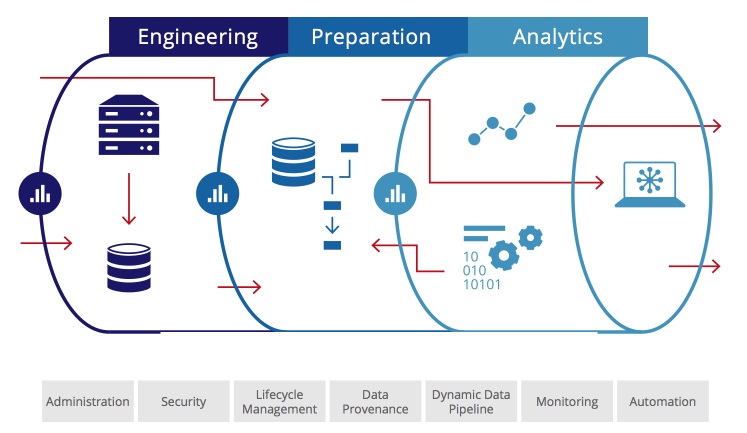
Following are some key steps and considerations for building efficient data pipelines:
- Define Pipeline Objectives: Clearly define the goals and objectives of your data pipeline. Understand what data you need to collect, process, and analyse, and what insights or models you aim to derive from it.
- Data Collection: Gather relevant data from various sources such as databases, APIs, files, or streaming services. Ensure that the data collected is accurate, clean, and in the right format for further processing.
- Data Cleaning and Preprocessing: Clean the data by handling missing values, outliers, and inconsistencies. Preprocess the data by standardising, normalising, or transforming it as required for analysis or model training. This step is critical for improving data quality and ensuring the accuracy of downstream tasks.
Preprocessing data is assuming increasing importance and is a serious topic in a Data Science Course because the volume of accessible data keeps building and identifying relevant data can be a daunting task.
- Feature Engineering: Generate relevant features from the raw data that can improve the performance of machine learning models. This may involve creating new features, combining existing ones, or encoding categorical variables.
- Model Training and Evaluation: Develop machine learning models using the processed data and evaluate their performance using appropriate metrics. Iterate on model development and tuning to improve predictive accuracy and generalisation.
- Model Deployment: Once a satisfactory model is trained, deploy it into production environments where it can make predictions on new data. Ensure that the deployment process is efficient and scalable, considering factors such as latency, throughput, and resource utilisation. Models based on machine learning are extensively being used in data science. Being a complex topic, only experienced mentors can demystify the principles of machine learning, a subject included in most data science courses. A quality Data Science Course in Hyderabad, for instance, might be engaging the services of an experienced professional to handle machine learning modules.
- Monitoring and Maintenance: Continuously monitor the performance of the data pipeline and deployed models. Set up alerts for detecting anomalies or degradation in performance. Regularly update and maintain the pipeline to accommodate changes in data sources, business requirements, or technology stack.
- Scalability and Efficiency: Design the data pipeline to be scalable and efficient, capable of handling large volumes of data and processing tasks in a timely manner. Utilise parallel processing, distributed computing, and cloud-based services to improve scalability and resource utilisation.
- Automation: Automate repetitive tasks and workflows within the data pipeline to reduce manual effort and human error. Use workflow management tools or frameworks to orchestrate and schedule data processing tasks efficiently. While automation is largely process-specific and its implementation specific to each business workflow, any Data Science Course will cover the basic theories and methods of automation, which must be fine-tuned to fit the business workflow to which it is applied.
- Documentation and Collaboration: Document the data pipeline architecture, workflows, and dependencies to facilitate collaboration among team members and ensure reproducibility. Maintain version control for code and configurations to track changes and facilitate collaboration.
Summary
By following these steps and considerations, you can build efficient data pipelines that enable effective data-driven decision-making and support the development of robust machine learning models in data science projects. The discipline and systematisation brought in by adhering to such pipelines will help professionals in applying data science effectively and thereby, excelling in their roles.
ExcelR – Data Science, Data Analytics and Business Analyst Course Training in Hyderabad
Address: Cyber Towers, PHASE-2, 5th Floor, Quadrant-2, HITEC City, Hyderabad, Telangana 500081
Phone: 096321 56744